Building Excellence in Digital
We partner with clients to build digital products, prioritizing excellence at every stage
Application Modernisation for an Enterprise
Explore how we aided an enterprise in their application modernisation journey
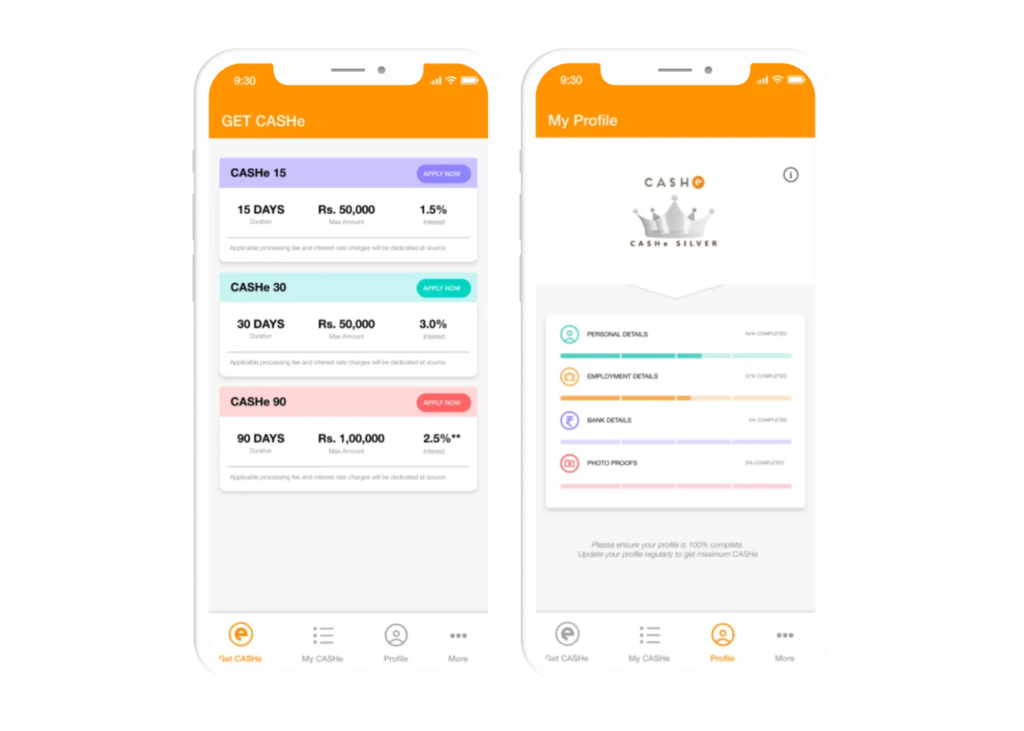
Our Impact for Fintech Clients
Discover our innovative product development for a new-age fintech organization
Elevating Digital Experiences
For over a decade, Byteridge has been a trusted partner to businesses across diverse industries, delivering bespoke software solutions that yield tangible outcomes. Leveraging our extensive experience, we empower clients to enhance efficiency, elevate user experiences, and achieve a competitive edge. Our proficiency extends from developing custom product solutions to application modernisation, mobile app development, and pioneering Gen AI technology.
Recognized as a Great Place to Work®, we foster a collaborative and innovative environment that underpins our clients’ success. Our commitment to employee satisfaction translates directly into exceptional results for our partners.
Explore our comprehensive suite of services and unlock your digital potential with Byteridge as your trusted partner.
Driving Tangible Results
Our solutions have consistently delivered measurable outcomes, and our metrics speak to our commitment to driving tangible results and client satisfaction.


Our Service Offerings
Product Studio
Transforming ideas into impactful digital products. Our Product Studio offers end-to-end product development, from conceptualization to launch, tailored to your needs.
Application Modernisation
Modernise applications for enhanced performance, improved user experience, and a competitive edge. Byteridge's expertise ensures a smooth transition to modern technologies.
Mobile App Development
Unlock the full potential of your digital presence with our tailored mobile app development solutions. Experience effortless connectivity and heightened user engagement like never before.
Gen AI
Leverage the power of AI to transform your business. Byteridge's Gen AI service delivers advanced AI solutions to streamline operations and accelerate growth.
Our Customers




























































Why Partner with Byteridge?
Unmatched Expertise
Leverage our team's wealth of experience and expertise in crafting scalable, bespoke solutions that provide enduring value over the long haul, ensuring continued success.
Strategic Approach
We believe in technology that drives results. Our agile approach ensures we adapt to market changes and your evolving needs, maximizing opportunities for growth.
Client-Centric Focus
Your success is our priority. We collaborate closely with you to understand your goals, ensuring our solutions not only exceed your expectations but also deliver measurable results, propelling your business forward.
Continuous Innovation
Stay ahead of the curve with our deep industry knowledge and technological expertise. We embrace emerging technologies like AI and ML to future-proof your digital initiatives.
Hear It From Our Customers

Sachin Somaiya
Manager, Tata Strategic Management Group Mumbai, India


Juhee Ahmed
Sr. Manager, Microsoft India


Ramnath Misra
Head Marketing & Strategy, Hindware India


Brad Wilton
Director of IT at Valley Proteins


Sreedhar Gunduboina
Sr. Product Manager, HR SaaS Company


Naveen H
Director, Electronics Product Manufacturer


Sid Pailia
Founder & CEO, Savings Solutions Provider


Eirik Sørensen
CEO, Færdin


Shawn Ovenden
Founder & CEO, Jeppedo Calgary, Canada


Amit Tuteja
Technology Head


Peter Mansour
CEO, IfUiWill Seattle, US


Kevin Leneway
Engineering Lead, Pioneer Square Labs Seattle, USA


Ruchit Garg
Founder & CEO, Harvesting California, US


Unni Nambiar
CTO / Co-founder, CASHe Bengaluru, India


Srikanth Chintalapati
VP Operational Excellence, Transportation Services


Nitin Kothavale
SVP of Technology, B2B Commerce Company


Choton Basu
Founder & CEO, Aikonik dba GivAmaze


Mamtha Banarjee
Founder & CEO, MagikFlix Inc. Seattle, US


Karan Uthaiah
Founder, TASC Global


Radhakrishna Mocherla
COO & Director, Algoleap Technologies Pvt Ltd


Naveen Puttagunta
CEO, Divami Design Labs


Nijo Lawrence
Game Producer, Moonfrog Labs Bengaluru, India


Ramu Kallepalli
CTO, TravelSpice.com


Sameer Maini
CEO, Collaborationroom.AI


Kiran Gopinath
Founder & CEO, Advertising Platform


Shailesh Goswami
Founder & CEO, Foyr Singapore


Siddharth Hemmadi
Co-Founder, Parinishtaa Media Ventures & Parinishtaa Eco Solutions


Mohit Arora
Executive, B2B E-Commerce Company


Vignesh Swaminathan
VP Product Management at ASG Technologies


Rijul Jain
Investments, Astarc Ventures Mumbai, India


Rajeev Aurangabadkar
Founder & CEO, GiftMyLegacy | India Hyderabad


Sameer Gujral
Director, B2B Lead Generation Company


Adithya Datla
Founder at Surreal Technologies


Srinivas Mogalapalli
Founder, Turaco Mobile Pvt Ltd

Punitha Anthony
VP of Product Management, Enterprise Software Company


Prashanth Rao
COO at Wozart

OUR PARTNERS
At Byteridge, we deeply value our collaborations with industry leaders who share our vision for excellence. Our partners are catalysts to our success, and we take pride in growing together. We unlock new possibilities and create meaningful impact in the ever-evolving technology landscape.